The computational burden of implementations of the iteration (3) has motivated the use of approximations for the function (7). However, as we have commented, there is a potential for
errors introduced by approximations to be magnified when realizing solutions to
ill-posed stochastic inverse-problems. For this reason, we have studied two
implementations of (3). The first, which is already in use
for restoring HST images, relies on an approximation to
obtained by substituting a Poisson variate for the read-out noise
in
Eq. (1). The second relies on an evaluation of
via a saddlepoint approximation.
We describe these two approaches in the remainder of this section. Results we have obtained using them are presented and compared in the next section.
For this approximation, we follow the discussion given by Snyder, Hammoud, and
White (1993, p. 1017). The read-out noise from the jth pixel is a
Gaussian-distributed random variable with mean
and standard deviation
. If the data
are modified to form
, thereby
converting the read-out noise to
, which is Gaussian
distributed with mean and variance equal to
, and if
is
large, then according to Feller (1968),
is approximately
equal in distribution to a Poisson-distributed random variable with mean
. With this approximation, the CCD data (1) become
where is Poisson distributed with mean
.
Under this approximation,
the data
form a
Poisson process with mean-value function
As there is now no Gaussian read-out noise, the iteration (3) becomes
which is the Richardson-Lucy iteration modified to accommodate
nonuniformity of flat-field detector-response and background noise.
This is equivalent to making the following
approximation to
in Eq. (7) when the standard
deviation of the read-out noise is large:
We note also from Eq. (7) that as tends to zero,
tends towards
, suggesting that the approximation
(11) for large values of
will be a good
choice for small values of
as well.
An alternative to the Poisson approximation is to evaluate the function (7) as needed for use in Eq. (3). However, this
function depends on ,
, and
in a complicated way, so some
numerical method of evaluation is necessary. We have used the saddlepoint
integration and saddlepoint approximation methods introduced by Helstrom (1978)
for calculating tail probabilities.
The Laplace transform of the Poisson-Gaussian-mixture density (8) is
and, by the inverse Laplace transform,
where
The saddlepoint integration and
saddlepoint approximation methods can be used with
(13) to produce
accurate evaluations of the function
in (7). The
saddlepoint
, which is real, is the root of
This root can be determined numerically using a Newton iteration,
where .
We iterate Eq. (16),
from starting values described below,
until
,
where we have used
as the tolerance parameter. The
saddlepoint approximation to Eq. (13) is
Useful starting values for the Newton iteration (16) can be obtained by making approximations to the exponential in Eq. (15). For example, replacing the exponential by two terms of its Taylor series,
and then solving suggests using
as a starting value.
Although this is adequate for some values of and
, for
low values of
combined with
large values of
, this resulted in starting
values so far from the saddlepoint that hundreds of Newton
iterations were required for
convergence (see Table 1).
We have developed two alternative approaches
for establishing more efficient starting values. One of these is
obtained via the Padé approximation (Newton,
Gould, and Kaiser 1961):
Solving this for in
terms of
and substituting the result
into Eq. (15) suggests using
as the starting value, where the sign of the radical is selected to make the
argument of the logarithm positive. Although the Padé approximation (20) is inaccurate for , we have found that
the Newton iterations (16) started with (21) converge, to within a tolerance parameter
, in no more than five iterations for
and
ranging from
to
for both
and
(see
Table 1). For this reason, we have generally used starting values
based on this approximation in all of our studies for a read-out noise level of
electrons. Another alternative is to use a small number of
Picard iterations
to solve Eq. (15). We start these iterations using
(19) and only perform a small number of them,
typically three, before converting to Newton iterations. Also, if the argument
of the logarithm in (22) becomes negative during the
Picard iterations, we revert to using (19) to
start the Newton iterations. With this approach, no more than five Newton
iterations were required for convergence to within a tolerance parameter of
in evaluating either the numerator or denominator of (7), and often one or two sufficed.
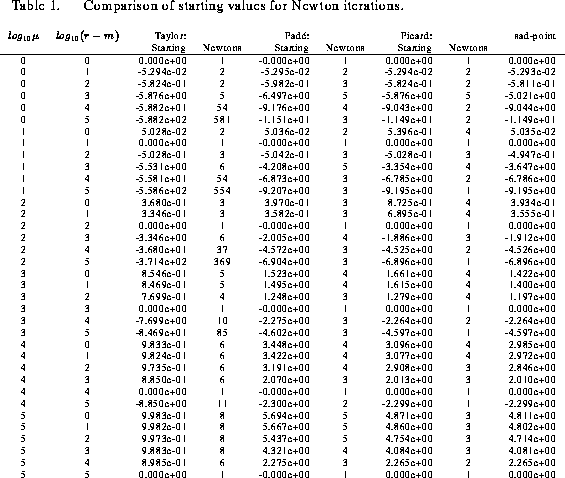
Shown in Table 1 are the starting values and the numbers of Newton
iterations required for convergence to a tolerance parameter of for each of the Taylor, Padé, and Picard methods for determining
starting values for
and a wide range of values of
and
. While a variety of starting values and numbers of Newton iterations are
seen, all three methods converged to the same saddlepoints to the degree of
numerical precision shown in the table. Both the Padé and Picard methods
required no more than 5 Newton iterations, while the Taylor method often
required many more.
Because of the wide dynamic range encountered
in HST images, with values of
ranging over several orders of
magnitude, it is necessary to modify Eq. (7)
to avoid overflow and underflow, writing it as
where in the saddlepoint approximation
Since the factors of cancel in
determining (7), we omit these
in our computations.
The saddlepoint integration
of Eq. (13) is performed
by integrating along the vertical
line ,
, through the
saddlepoint to obtain
The trapezoidal rule was used, taking the step size as and stopping the
summation when the absolute value of the integrand fell below
times the accumulated sum, with
. Smaller step-sizes did not
noticeably alter the results, which were also checked by evaluating Eq. (7) with the summation in Eq. (8); the
results agreed to at least six significant figures. The discrepancies may be
attributable to round-off error in the summations in Eq. (8).
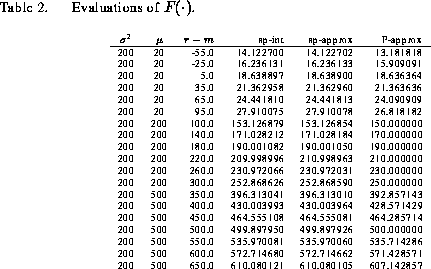
Shown in Table 2 are values of obtained for the
methods of saddlepoint integration (Eq. 25),
saddlepoint approximation (Eq. 17), and Poisson
approximation (Eq. 11) for
and several
values of
and
. One purpose of this table is to compare ``exact"
values obtained with saddlepoint integration to values obtained with the
saddle-point and Poisson approximations. Starting values for the Newton
iteration were determined by the Picard method. The saddlepoint approximation
is seen to agree closely with the results of saddlepoint integration. If we
take the values of
obtained in Table 2 by
saddlepoint integration as ``exact," then the sum of absolute errors for the
saddlepoint and Poisson approximations differ by several orders of magnitude,
being 0.0004 and 19.81, respectively.
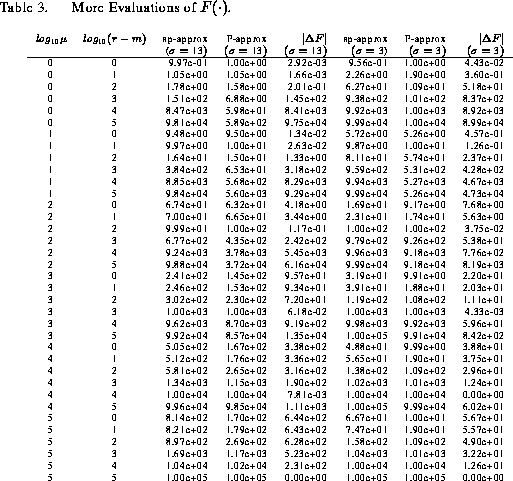
Shown in Table 3 are values of obtained for the
methods of saddlepoint approximation, using Eqs. (23)
and (24), and Poisson approximation
(Eq. 11) with
, corresponding to the
level of read-out noise present with the HSTs CCD camera, and
,
corresponding to possible values of read-out noise present with improved CCD
cameras, for a wide range of values of
and
. The purpose of this
table is to compare values obtained with the saddlepoint and Poisson
approximations over a dynamic range encountered in HST image data. In this
table,
is the magnitude of the value of the difference in values
of
determined by the saddlepoint and Poisson approximations.
The saddlepoint and Poisson approximations are seen from these tables to
produce practically identical results for . Elsewhere, the
Poisson result is consistently less than the saddlepoint result, with the
difference worsening as
strays further and further from
. For
, the error tends to level off to some value, whereas for
,
the error rises rapidly and somewhat proportionately to
. The percentage
error can be quite large, especially when
is much larger than
.
For instance, for
,
and
,
/(sp-approx)=99.4%.
In performing Newton iterations to evaluate in Eq. (7), the saddlepoint for the denominator was evaluated first, and
the saddlepoint then determined was used as the starting value for Newton
iterations in evaluating the numerator. Except when
was close to
,
the number of Newton iterations for the numerator was then no larger than for
the denominator and was usually smaller.
A C subroutine to compute using the saddlepoint approximation
with a Newton iteration to determine the saddlepoint is given in the Appendix
for starting values obtained with either the Padé or Picard methods. With
and
, which are typical values,
calls of
these subroutines take approximately 16 seconds on a SUN Sparcstation IPC and 8
seconds on a SUN Sparcstation IPX. These times can probably be lowered
substantially while maintaining nearly the same accuracy by using a larger
value for the tolerance parameter
.
We have implemented the EM iteration (Eq. 3) on a DECmpp
12000Sx / Model 200 single-instruction multiple-data (SIMD) computer with a
6464 processor array. Ideally, images would be mapped directly with
one pixel per processor. Since, in these simulations, we perform computation
on images of dimension 256
256 pixels, zero padded to 512
512,
64 pixels are stored per processor. Convolutions are computed with FFT
algorithms tailored to take advantage of the SIMD architecture. The additions,
multiplications, and division in (3) are performed for
pixels in parallel. Both the Poisson and saddlepoint approximations (using
Padé's approximation) have been implemented. Each processor computes values
of F for its pixels independently of the other processors, which is ideal for
SIMD architectures. For a
image (the data must be zero-padded
so that the point spread does not wrap around), we can compute 50 EM-Poisson
iterations in approximately 61 seconds and 50 EM saddlepoint iterations in
approximately 81 seconds. The exact times for the EM saddlepoint iterations
depends upon the number of Newton iterations required, which depends upon the
data. If machine precision or other factors cause
to be zero for some
pixels, the denominator in Eq. (21) will be zero.
In that case, we take the ratio
in the EM algorithm (3) to be zero.